

Perplexity Just Automated Model Testing.
Stop wondering if Opus 4.6 is better. Model Council runs Claude, GPT, and Gemini simultaneously and shows you where they agree. Or don't.

Everyone is hyped about Opus 4.6.
Your feed is full of comparison posts. Screenshots showing Claude vs GPT. Threads debating which model is smarter.
You have one question: Is it actually better for what you need?
Perplexity just released a feature that stops you from having to figure it out.
The Testing Trap We’re All Stuck In
You know the drill.
New model drops. You spend two hours testing it. You run your actual prompts through Claude, then GPT, then Gemini. You compare the outputs. You try to figure out which one understood your context better.
You take notes. Claude for writing. GPT for research. Gemini for coding. Vice versa. You build a mental spreadsheet of which model works best for what.
Then next month, another model releases. You do it all over again.
If you’re a [LinkedIn] creator, you spend entire afternoons on this. You share screenshots. You debate in the comments. You refine your mental rules about which AI to use when.
Those rules expire the moment the next model ships.
Model Council: What It Actually Does
Perplexity launched Model Council this week.
It runs your prompt through Claude Opus 4.6, GPT-5.2, and Gemini 3.0 simultaneously. You see all three answers. You see where they agree. You see where they conflict.
No more guessing. No more testing. No more wondering if you picked the wrong model.
A synthesizer model reviews the three outputs and shows you:
Where models converge (high confidence)
Where models disagree (needs verification)
Unique discoveries only one model found

The catch? It’s Perplexity Max only. $200/month or $2,000/year. Not available to regular users.
The Hours This Could Save
Think about how much time you spend on model selection right now.
Testing new releases. Reading comparison threads. Switching between platforms. Maintaining subscriptions to three different services.
LinkedIn creators spend hours every week comparing outputs and sharing what they learned. Technical writers maintain guides on which model to use for which task. Developers switch between Claude for one problem and GPT for another.
That’s the overhead of fragmentation.
Model Council automates it. The system picks. The system compares. The system highlights differences.
You focus on the work instead of the tooling
What Each Model Actually Brings
The three models in Model Council each have real differences.
Claude Opus 4.6 excels at nuanced writing, coding, following complex instructions, and maintaining context over long conversations.
GPT-5.2 performs well at coding, structured reasoning, and tasks requiring broad knowledge integration.
Gemini 3.0 Pro handles multimodal tasks, large context windows, and integration with Google’s ecosystem.
When you query all three simultaneously, you’re not just getting redundancy. You’re getting different analytical approaches to the same problem.
One model might cite sources the others missed. One might frame the answer differently. One might catch an error the others made.

Where This Gets Interesting
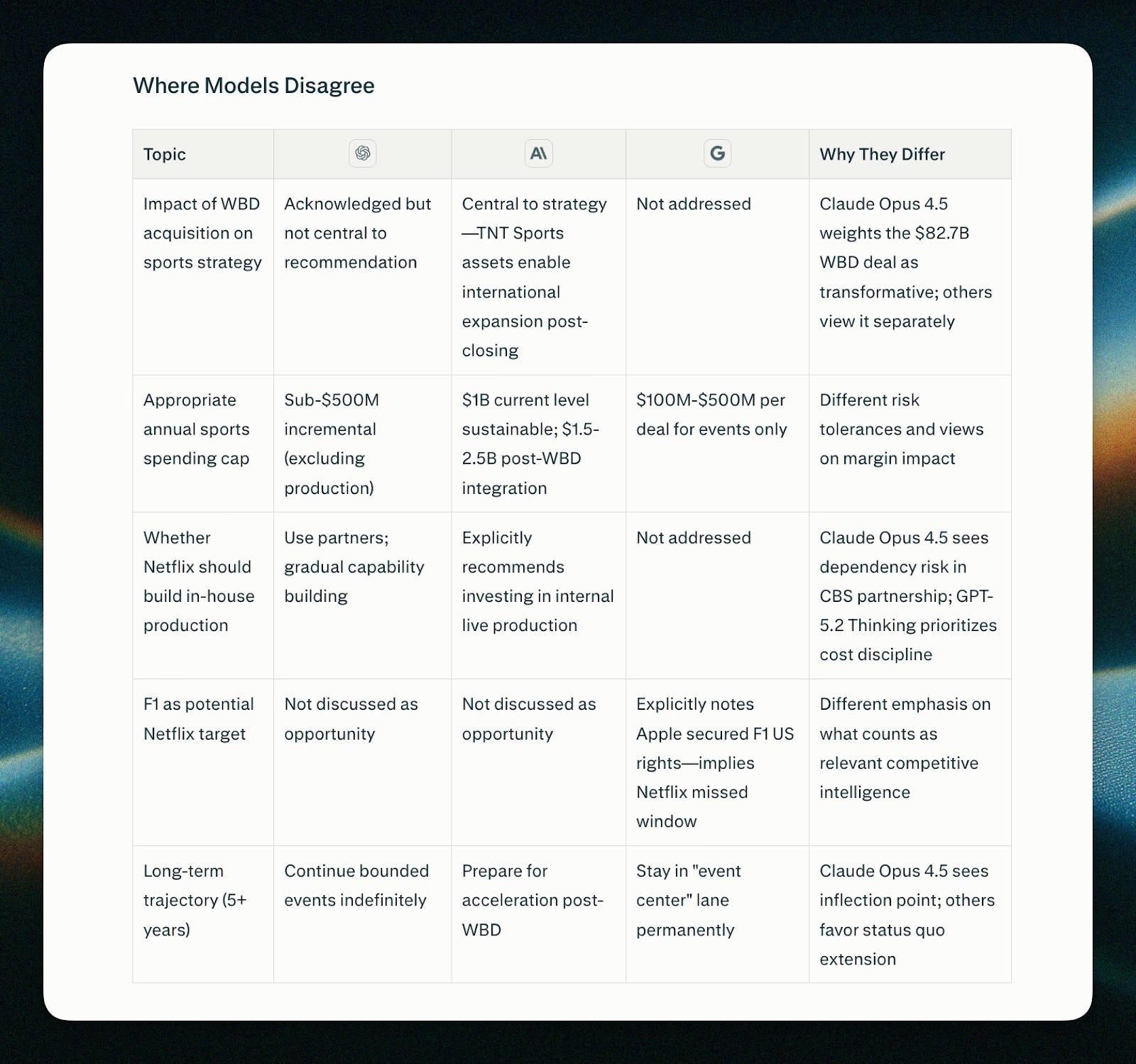
Model Council reveals something most people don’t see: how often AI models disagree.
We treat AI answers as authoritative. The model gives you a confident response. You assume it’s correct. You move forward.
But run the same prompt through three different models and you’ll see divergence you didn’t expect.
Different emphasis. Different sources. Different conclusions.
That’s not a bug. That’s the current reality of frontier AI models.
Model Council makes the divergence visible instead of hidden. You see where confidence is warranted and where it’s not.
Reality Check
Model Council won’t transform your workflow overnight.
It’s expensive. $200/month is steep compared to $20/month for individual model subscriptions.
It’s slower. Querying three models plus running a synthesizer takes more time than querying one.
It’s web-only. No mobile app support yet.
The synthesizer itself can make mistakes. You’re adding another AI layer that could introduce errors instead of fixing them.
For quick questions with straightforward answers, a single model is probably fine. Model Council makes sense for high-stakes queries where you’d manually cross-check anyway.
Who Needs This Right Now
You’re a good candidate if you:
Already cross-check answers between different AI platforms
Make decisions where accuracy directly impacts outcomes
Research topics with multiple legitimate perspectives
Write content that requires verification
Have budget for a Max subscription
You don’t need this if you:
Use AI for quick lookups and simple tasks
Can’t justify $200/month for the use case
Prefer seeing individual model responses and making your own comparisons
Work primarily on mobile
The Future I’m Hoping For
Model Council is expensive and limited right now.
But the pattern it represents is where I hope we’re headed.
I want AI platforms to consolidate. I want to stop maintaining separate accounts for Claude, ChatGPT, and Gemini. Stop copying prompts between services. Stop losing conversation history when I switch models.
One interface. Multiple models working together. Your data stays in one place.
The models themselves might even collaborate. One model good at research finding sources. Another model good at analysis processing them. A third model good at synthesis pulling it together.
We’re watching the shift from AI as separate tools to AI as an integrated system.
Model Council is version 0.1 of that future.
The question I ask myself is whether we actually get there.
Each AI company wants to be the frontrunner. OpenAI wants you locked into ChatGPT. Anthropic wants you on Claude. Google wants you in Gemini.
Consolidation only happens if the economics favor platforms over individual model providers. If users demand it loudly enough. If the friction of fragmentation becomes too costly to ignore.
Right now, competition drives model improvements. But it also drives fragmentation.
We might end up in a world where model orchestration becomes standard. Or we might end up with stronger walled gardens where each company tries harder to keep you in their ecosystem.
Model Council suggests the first path is possible. Whether it becomes inevitable depends on what users choose and what companies decide is more valuable than control.
What This Means For You
The model release hype will continue.
Opus 4.6 today. Something else next month. Each one marketed as a breakthrough. Each one triggering another round of testing and comparison.
You can keep playing that game. Keep testing. Keep comparing. Keep switching.
Or you can wait for platforms to automate it for you.
Model Council is the first commercial product that does this at scale. It won’t be the last.
The question isn’t whether to use Model Council specifically. The question is whether you’re ready for a world where model choice becomes invisible infrastructure instead of a decision you make every time.
Getting Started
If you want to try Model Council:
You need a Perplexity Max subscription ($200/month or $2,000/year)
It’s available on web only (no mobile apps yet)
Select Model Council before submitting your query
Review the combined answer and flagged differences
Use it for high-stakes queries where verification matters
If you’re not ready for Max pricing, watch this space. Other platforms will follow. The pattern matters more than the specific implementation.
The Honest Truth
Model Council solves one specific problem: the mental overhead of picking the right model and wondering if a different one would have been better.
It doesn’t make AI suddenly reliable for everything. It doesn’t eliminate the need to verify important information. It doesn’t mean you can stop thinking critically about AI outputs.
It automates comparison. That’s valuable if comparison is part of your current workflow anyway.
If you’re already spending hours testing models against each other, Model Council saves you that time. If you’re not, it probably doesn’t change much for you yet.
The feature matters less as a tool you need today and more as a signal of where this is going.
Model Council is the first step. Watch what comes next.
→ What task are you still testing across multiple models?
This article is part of my ongoing series on making AI simple and useful for non-tech people. Subscribe to get future articles on AI tools that actually matter for everyday life. It means a lot to me.